

The System Administrator for the City of St. Paul, MN, walks us through the best practices used in setting up a Quick Fields session.
Our department works with three different types of documents on a regular basis: Agendas, Minutes, and Budget Minutes. We started with a Quick Fields session that processed around 25 pages a second. This may not sound like a bad rate, but by taking advantage of all the functionalities that Quick Fields has to offer, we were able to increase our processing rate to over 300 pages a second!
Set-up
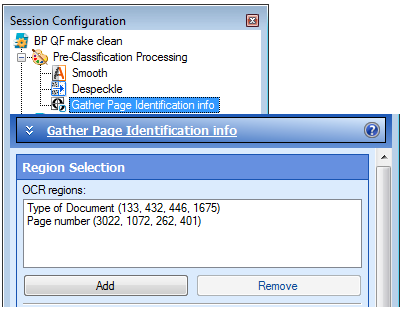
Each document is despeckled, smoothed and zone OCR’d for identification. We use two zones for identification: the title area and the page number. The Agendas and Minutes start with Page 1, while the Budget Minutes begin with a cover page without a page number. Lastly, we use Zone OCR to gather information on the meetings, i.e. type, place, time, and date.
Pre-Classification Processing
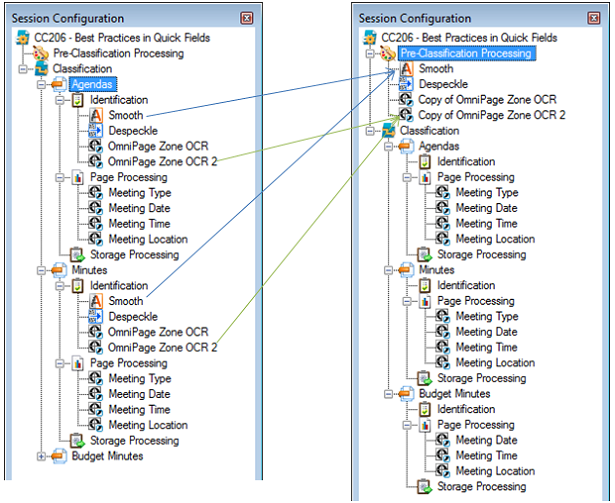
As part of streamlining the Quick Fields session, we moved Despeckle, Smooth, and the Identification Zone OCR’s, which occurred for all independent ID processes, to Pre-Classification Processing.
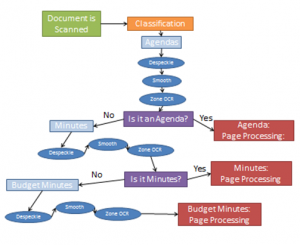
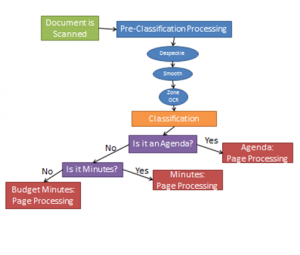
The benefits of Pre-Classification Processing are evident when looking at the two flow charts below. The first chart describes the process without utilizing Pre-Classification Processing, while the second chart describes this same process with Pre-Classification Processing. Try following the map for Budget Minutes. The length of this path should illustrate the benefits of Pre-Classification Processing.
Also, we have greatly increased the performance of the Quick Fields Session by getting rid of two resource-intensive Zone OCR Processes.
Zone OCRs performed in the Pre-Classification Processing step only store information as tokens; no identification occurs. We have to create unique identification conditions for each document type under the Classification step.
Hint: Give your processes intuitive names that concisely describe what the process is doing. This will help you trouble-shoot.
- We renamed the Zone OCR processes to something that makes more sense. Now we know what is happening just by looking at the Quick Fields session configuration
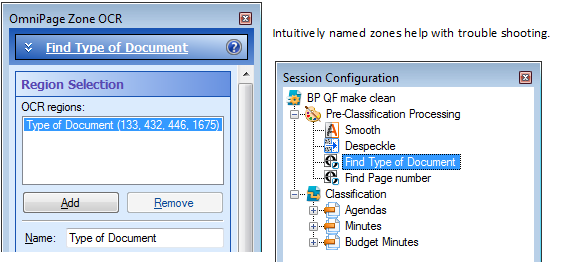
Quick Fields 8 allows you to use one zone process with multiple zones in order to streamline your OCR processes (more on this later).
Logical Operators
Now that we have two identification zones, we need to add separate Token Identification Processes for each document type, since this is not incorporated into the Pre-Classification Process. Since we are dealing with three types of documents we created a Token Identification condition to determine the document type.
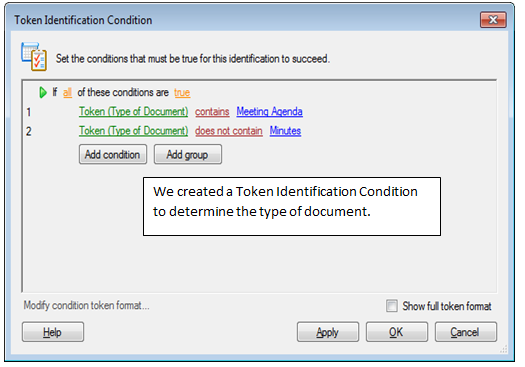
In order to decide if our statements will limit or expand the search we have to choose between “all” and “any” for the first orange word. Within the Identification Conditions you can check if a token matches a given, static value (number or word).
For help with Quick Fields Logical Conditions see: Help.
Don’t worry, if you make a syntax error, the program will catch it with a red exclamation mark. Just click on the exclamation mark for a hint about what is wrong.
Page Processing
We use this step to gather all the relevant data from the documents to insert into our template fields; in this case, meeting minutes.

Each agenda has a page with the date of the meeting, the time of the meeting and the location of the meeting. We can assign all the zones to one OCR process as we did earlier in Pre-Classification Processing. We can combine all of the zones into one larger zone that contains the desired information on the page. Later, we will use pattern matching to extract the pieces of information we want from the zone.
Hint: If you change what information is contained within a zone, update the associated tokens.
Pattern Matching
Pattern Matching allows us to use fewer zones and get more out of them by taking advantage of the structure of a string to extract the pieces of information in which we are interested.
Quick Fields uses .NET Regular Expressions for its Pattern Matching feature. For an in-depth advanced reference as to what these regular expressions are and how to use them, visit Regular Expressions.
In order to take advantage of Pattern Matching, we must first find the pattern in our information. The three pieces of data we want to extract from our large zone above are the Date, Time and Place of the meeting. Their patterns are:
- Every Meeting Date has the format, “Day comma Month number comma Year”.
- Every Meeting Time has the format, “one or two digits colon two digits A or P M” with no spaces.
- Every Meeting Place is, “Council Chambers hyphen number two letters Floor” with an arbitrary number of spaces.
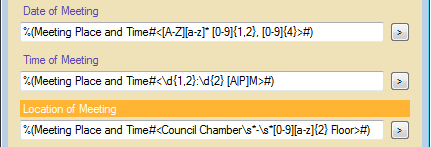
The above image illustrates the regular expressions that match the patterns for our sought after information and tells the computer which tokens to look in for the information.
Five Things to Keep in Mind when Designing your Quick Fields Session
- Streamline and minimize your resource-heavy processes by using Pre-Classification Processing.
- Name your processes descriptively.
- Use care with logical operators when creating Identification Conditions.
- Organize the information you want to retrieve into one Zone OCR Process.
- Create large zones and use Pattern Matching to extract the relevant information.
We hope that our experience will encourage you to try out a few of these practices in your own Quick Fields sessions.