


Contributed by:Joanna Slusarz, Technical Writer, Laserfiche
Regular expressions (also known as Pattern Matching expressions) are a way of defining patterns in information by using special symbols. In Laserfiche Quick Fields, these expressions can be used to identify documents or extract information in order to properly populate fields or set the document location in the Laserfiche repository. Different types of characters, such as word characters, decimal numbers and whitespaces, are represented by particular symbols.
Processes and features in Laserfiche Quick Fields that use regular expressions include:
- Pattern Matching
- Auto-Annotation
- Substitution
- Tokens
- Text Identification
These processes can be performed on the document’s text, name, field values or data from a third-party data source. Before using any of the processes on the document’s text, you must first extract this text from the document using one of the text extraction processes provided by Laserfiche Quick Fields.
Please note that in order to use regular expressions in Laserfiche Quick Fields, the Pattern Matching add-on is required.
The scenario
For the purposes of this article, we are going to use the example of a medical clinic that regularly scans all of its patient records including new patient information forms, lab results and insurance cards. All of the patient records have the following template assigned to them:

Here is how we can use regular expressions in conjunction with Pattern Matching, Substitution, Auto-annotation, Token Editor and Text Identification within a Quick Fields session to process these medical records.
Pattern Matching
The Pattern Matching process looks for a specified pattern within a user-defined value and converts this information into a token that you can then insert into a field to store as part of the document’s metadata.
Example: When scanning in patient records at a medical clinic, you have to extract “Patient ID” from a different place in each document. You know that “Patient ID” always follows the same pattern of three letters followed by a dash and five digits. When processing this paperwork with Laserfiche Quick Fields, you can use Pattern Matching to pick out this ID from the text and insert it into a corresponding template field.
You can perform Pattern Matching on either the document text or on a token. In this case, we would like to perform it on the document text. We can use two different patterns here that will give us the same result:
- www-ddddds
- w{3}-d{5}s (Instead of specifying the individual characters, list their quantity in curly brackets.)
‘w’ represents any word character, ‘d’ represents any digit and ‘s’ represents a space.
Since “Patient ID” can appear anywhere on the document, we will make sure to search the entire document and not just a certain section.

Detailed, step-by-step instructions for configuring Pattern Matching can be found in the Online Help Files.
Substitution
The Substitution process allows you to find and replace words in page text or tokens using regular expressions. It is useful for correcting errors or changes made during OCR.
Example: When processing the “New Patient Information Sheet,” phone numbers are sometimes OCRed with spaces in between the dashes. In addition, the phone numbers on the form are written with parentheses around the area code, but in order to facilitate searching, they need to be stored in an xxx-xxx-xxxx format instead. You can configure a Substitution process to find all phone numbers and convert them into the xxx-xxx-xxxx format when inserting them into the template field.
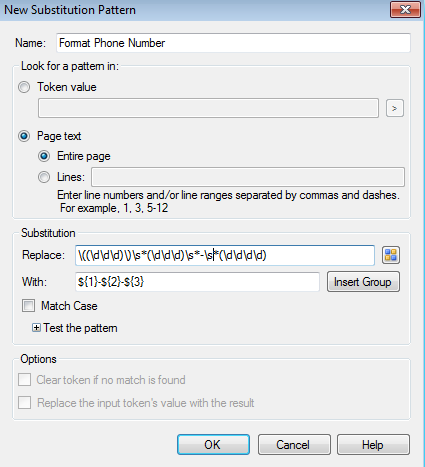
In order to configure the Substitution process, you will first need to search for the following pattern: ((ddd))s*(ddd)s*-s*(dddd)
The colored parentheses signify match groups—groups of information to be used in the actual substituted pattern. You can use these match groups in the substitution by clicking the “Insert Group” button and then choosing the groups in the order that you would like them displayed along with anything else you may want to include. In this case, we want to include a dash: ${1}-${2}-${3}
If the Substitution process finds text that matches the first pattern, it will replace it with the second pattern: (310) 344- 0989 will become 310-344-0989.
Detailed, step-by-step instructions for configuring a Substitution process can be found in the Online Help Files.
Auto-Annotation
Auto-Annotation adds Laserfiche annotations to text that fits a certain specified pattern. The annotations will be applied to an imaged document and its associated text, or to the text associated with an electronic document (but not the electronic document itself).
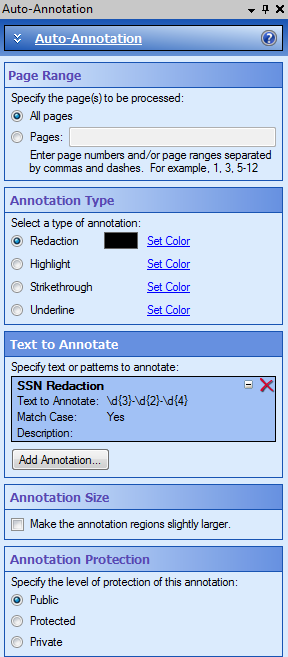
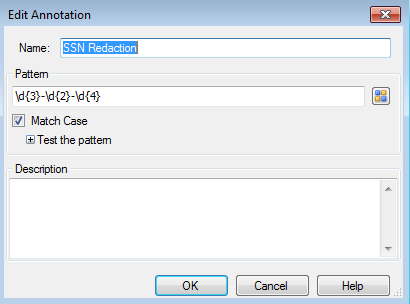
Example: Due to patient privacy laws, any time a Social Security Number appears on a document, it needs to be redacted. You can configure an Auto-Annotation process to search for a Social Security Number and redact it automatically.
We can use the following pattern: d{3}-d{2}-d{4}
Detailed, step-by-step instructions for configuring the Auto-Annotation can be found in the Online Help Files.
Token Editor
In Laserfiche Quick Fields, you can use regular expressions to extract specific patterns of information from tokens. You can use regular expressions to modify the token’s value in the Token Editor.
Example: Every patient is assigned a primary care physician. This information is stored in the Medical Clinic Database where each “Patient ID” corresponds to the full name of the doctor. In order to facilitate searching, you would like to store only the doctor’s last name in the “Doctor_Name” field. You can configure a Lookup process to pull the doctor’s complete name from the database, and then use the Token Editor to extract only the last name.
First, set up the Lookup process per the instructions specified in the Online Help Files. In this scenario, Lookup will return the doctor’s name as a token named %(Lookup_Primary_Doctor). Now we will configure this token to extract only the doctor’s last name.
- Find the “Doctor” field in the Document Properties view in the Tasks Pane and insert the %(Lookup_Primary_Doctor) token. Select it, right-click on the selection and choose Token Editor.
- We will use a regular expression to modify the retuned value. In this case the pattern will be: s(w+)$ This pattern extracts only the last word in the token. In this case, it is the doctor’s last name.
- When we modify our token to include this expression, it will now read: %(Lookup_Primary_Doctor#<s(w+)$ >#)
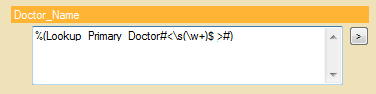
If the doctor’s name is listed in the database as “Sara M Klein”, then the “Doctor_Name” field will only read “Klein”.
Text Identification
The Text Identification process sorts documents into classes based on whether page text matches a specified pattern.
Example: All lab results are going to have “Laboratory” somewhere in the title, but because these documents may come from different labs and be in different formats, we want to set up a Text Identification process that searches the top half of the document for the word “Laboratory” and then classifies the document as lab results. In addition, sometimes the font used results in spaces between the letters when the document is OCRed so we want to account for that in our pattern.
In this case, you can use this pattern: Ls?As?Bs?Os?Rs?As?Ts?Os?Rs?Ys*
Detailed, step-by-step instructions on configuring Text Identification can be found in the Online Help Files. Additional resources A much more in-depth analysis of regular expressions, along with a regular expression reference and some frequently used patterns can be found in this comprehensive white paper: Pattern Matching and Token Formatting in Quick Fields 8. Please note that you need a Support Site login to download the white paper.